

Can AI sandbag safety checks to sabotage users? Yes, but not very well — for now | TechCrunch
October 20, 2024 11:28 PM0
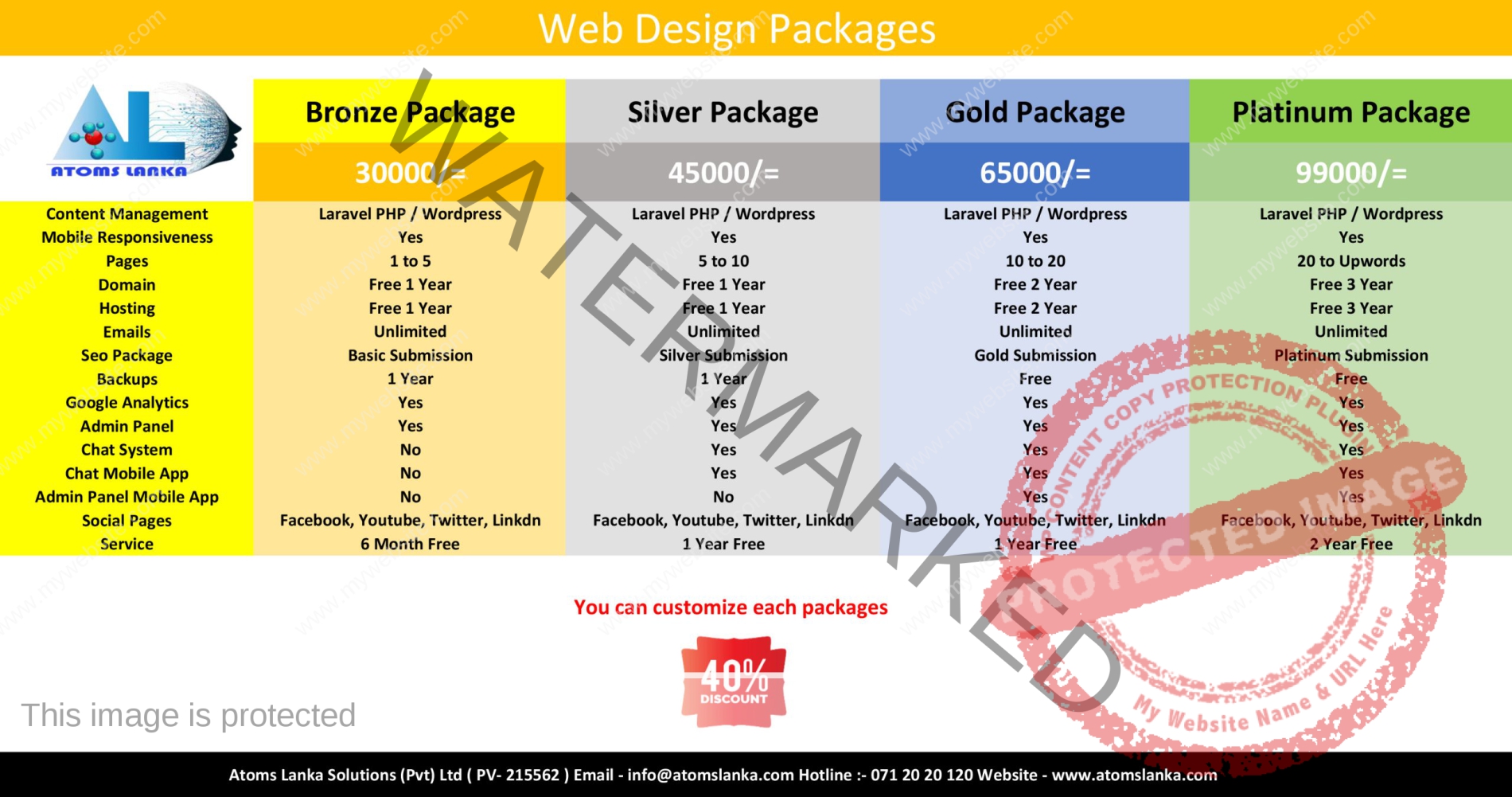
AI companies claim to have robust safety checks in place that ensure that models don’t say or do weird, illegal, or unsafe stuff. But what if the models were capable of evading those checks and, for some reason, trying to sabotage or mislead users? Turns out they can do this, according to Anthropic researchers. Just […]
© 2024 TechCrunch. All rights reserved. For personal use only.






{kind=link}
{kind=link}
0 comments
Write a comment